

한글은 세종대왕 머리에서 뚝딱 만들어진 것이 아니다. 여러 나라의 문자를 참고하여 만든 것이다. 수메르 설형 문자(쐐기문자)는 서방에서 사라졌는데 그와 비슷한 한자는 동방에 여전히 살아 있다. 원래 한나라 시대의 한자는 상형문자였다. 당송 시대에 지금처럼 획으로 표현하는 설형 문자와 비슷하게 된다. 한자의 원리는 실제로 설형 문자의 원리와 같다. 인간 머리는 거기서 거기다.
서방에선 이집트 상형 문자가 점차 표음 문자로 발전한다. 처음엔 음절 문자가 생기는데 받침소리가 거의 없는 일본어, 로마 라틴어 같은 언어에 적합하다. 이런 받침 없는 언어는 50개 정도의 문자로 소리를 표현할 수 있다. 그 후에 자음, 모음, 받침을 구분하는 음소 문자로 발전한다. 일본 문자가 한글보다 먼저 만들어진 것이다. 나중에 만들었다면 한글과 비슷했겠지.
이집트 상형문자에서 페니키아 표음 문자가 나오고, 거기서 그리스 알파벳이 탄생하고, 로마인들도 그 영향을 받아 로마 알파벳을 만든다. 로마 알파벳은 현재 영어와 서유럽에서 쓰고 있다. 러시아 사람들도 그리스/로마 둘의 영향을 받아 자기들 키릴 문자를 만들었다. 유럽엔 이렇게 3종류의 알파벳이 있다. 페니키아 옆의 아람 문자는 중동 아랍 문자의 조상이다. 아람어는 그 지역 공용어였다. 예수도 이 언어로 설교했다. (아람 ≠ 아랍)
이슬람에 의해서 중동의 아랍문자가 중앙아시아 초원에 퍼진다. 몽고족이 위구르 문자의 영향을 받아 자기들 문자를 만들고, 이건 만주족으로 이어진다. 그래서 그런지 아랍문자처럼 꼬불꼬불하다. 단지 쓰는 방향에 차이가 있다. 아랍(우→좌), 동양(상→하), 서양(좌→우). 만주 문자는 馬말 모양이 대단히 많다. 그러니가 馬말이 어떤 일을 할 때의 장면이 바로 그 단어의 첫소리를 의미하는 식이다.
몽골 제국이 국제 공용 문자로 개발한 것이 파스파 문자이다. 외국어 발음 기호로 사용하기 위한 문자로 만든 것이다. 이건 인도, 티베트 문자의 영향을 받은 것이다. 이 문자들은 불교 문화권의 문자이다. 동양에선 한글 이전 가장 좋은 문자이겠다. 한글이 이 영향을 안 받았다고 하는 건 무리겠다. 표음 문자의 원리는 모두 같다.
서방에선 이집트 상형 문자가 점차 표음 문자로 발전한다. 처음엔 음절 문자가 생기는데 받침소리가 거의 없는 일본어, 로마 라틴어 같은 언어에 적합하다. 이런 받침 없는 언어는 50개 정도의 문자로 소리를 표현할 수 있다. 그 후에 자음, 모음, 받침을 구분하는 음소 문자로 발전한다. 일본 문자가 한글보다 먼저 만들어진 것이다. 나중에 만들었다면 한글과 비슷했겠지.
이집트 상형문자에서 페니키아 표음 문자가 나오고, 거기서 그리스 알파벳이 탄생하고, 로마인들도 그 영향을 받아 로마 알파벳을 만든다. 로마 알파벳은 현재 영어와 서유럽에서 쓰고 있다. 러시아 사람들도 그리스/로마 둘의 영향을 받아 자기들 키릴 문자를 만들었다. 유럽엔 이렇게 3종류의 알파벳이 있다. 페니키아 옆의 아람 문자는 중동 아랍 문자의 조상이다. 아람어는 그 지역 공용어였다. 예수도 이 언어로 설교했다. (아람 ≠ 아랍)
이슬람에 의해서 중동의 아랍문자가 중앙아시아 초원에 퍼진다. 몽고족이 위구르 문자의 영향을 받아 자기들 문자를 만들고, 이건 만주족으로 이어진다. 그래서 그런지 아랍문자처럼 꼬불꼬불하다. 단지 쓰는 방향에 차이가 있다. 아랍(우→좌), 동양(상→하), 서양(좌→우). 만주 문자는 馬말 모양이 대단히 많다. 그러니가 馬말이 어떤 일을 할 때의 장면이 바로 그 단어의 첫소리를 의미하는 식이다.
몽골 제국이 국제 공용 문자로 개발한 것이 파스파 문자이다. 외국어 발음 기호로 사용하기 위한 문자로 만든 것이다. 이건 인도, 티베트 문자의 영향을 받은 것이다. 이 문자들은 불교 문화권의 문자이다. 동양에선 한글 이전 가장 좋은 문자이겠다. 한글이 이 영향을 안 받았다고 하는 건 무리겠다. 표음 문자의 원리는 모두 같다.
상형 문자를 표음 문자로 만드는 방법은 간단하다. 예를 들어 말(동물) 그림이 있고 그 소리가 “말”이라면 말 그림이 바로 동물(말)이 아닌 “말”이란 소리를 대신하게 되는 식이다. 비슷하게 소 그림이 소가 아니라 그냥 “소”라는 소리를 대신하게 된다. 일본은 한자를 빌려 음절 문자를 만든다. 원리는 비슷하다. 한자의 뜻은 버리고 독음만 취하는 식이다.
처음엔 자음으로만 사용하다가 누군가 모음 표시에도 사용하게 된다. 중동 페니키아 알파벳, 아람 문자, 아랍 문자 계통은 모음 표시를 하지 않는다. 처음 모음 표기는 자음 옆에 점을 찍는 식이었다. 그러다 다른 민족이 안 쓰는 자음을 모음으로 사용하기 시작한다. 선과 점으로만 표시하는 한글 모음을 보면 중동 문자의 영향도 받았음을 알 수 있다.
세종대왕은 만주를 통해 아시아 문자, 몽고 표음 문자, 일본 음절 문자, 중국 한자를 참고하여 한글을 만들었다. 음소 분리에 대해선 이미 이 글자들을 공부하면 간단하게 해결 된다. 한글의 대단한 점은 자음의 형상이 발음 기관의 상형 문자라는 점과 모음을 점과 선으로 표기하는 점이다. 문자 진화의 종점을 찍게 된 것이다. 공짜로 숟가락 얹은 게 아니다.
한글이 그 어떤 문자도 참고하지 않고 세종대왕과 집현전 홀로 독창적으로 만들었단 말은 개소리다.
모방은 창조의 엄마! 발견은 발명의 아빠! 발명은 필요의 부모!
사람 머리는 거기서 거기. 모든 것은 진화다. 진화는 신의 섭리!
지금은 한글 처리를 O/S가 해 주니까 직접 만들어야 할 일은 없겠지만 때론 비행 중에 무인도에 떨어지기도 하니, 불 피우고 낚시하는 법 알고 있어야 하듯이 한글 처리 기본은 알고 있어야 하겠지. 한글도 알파벳 ASCII 코드처럼 코드(숫자)를 부여해야 한다. 인터넷 검색하면 다음과 같은 것이 나온다.
1. 문자 코드 조립
- N 바이트 코드 : 자음, 모음에 알파벳처럼 1바이트 할당
- 3 바이트 코드 : 초성, 중성, 종성에 각각 1바이트 할당
- 2 바이트 코드 : 초/중/종 5비트 조합형, 유니코드, 음절 단위 완성형
한글은 초성, 중성, 종성을 정사각형에 모아서 한자처럼 쓴다. 그런데 알파벳처럼 음소를 옆으로 풀어 쓸 수도 있다. 그와 비슷한 것이 N바이트 코드이다. 이 경우 초성과 종성(받침)의 구분이 없다. 자음과 모음의 구분만 있다. 그래서 음절 구분이 어렵다. 그래서 초성과 종성을 구분하는 3바이트 코드가 생기는데 이렇게 하면 음절 구분이 쉽다. 3바이트 = 1음절.
이걸 2바이트에 압축해 넣는 방법이 나왔는데 완성형, 조합형, 유니코드(16비트)이다. 완성형은 한글을 한자처럼 음절 단위 문자로 본 것이니 음소 구분이 불가능하다. 한글보다 한자에 중심을 주어서 한자를 4888자 배치하고 남은 약 2천 개에 한글을 배치하였다. 부족한 한글은 확장 코드를 붙여 3바이트 초/중/성을 나열하는 식이다. 이걸 한글 코드라고 해야 하나? 중국 코드 아냐? 한글이 모자라서 MS사에서 띨띨한 한국인 불쌍하다며 CP949라고 추가 코드를 만들었다.
조합형은 조립형이라 음소 구분이 가능한데 코드의 낭비가 있다. 거의 사용하지 않는 한글 문자에도 코드가 부여되었다. 사용하지 않는 한글 소리를 모두 나열하면 1만 자가 넘는다. 당연히 한자 넣을 공간이 없다. (아니 머리를 잘 썼다면 충분히 있지.) 조합형, 완성형 이 둘은 ASCII 코드와 호환 되도록 만들었기 때문에 코드의 낭비가 있다. 제어 문자를 피해야 하기 때문이다. 또한 1바이트 아스키 코드인지 2바이트 한글 코드인지를 구분해야 하기 때문에 거의 50% 공간을 낭비한다.
조합형은 조립형이라 음소 구분이 가능한데 코드의 낭비가 있다. 거의 사용하지 않는 한글 문자에도 코드가 부여되었다. 사용하지 않는 한글 소리를 모두 나열하면 1만 자가 넘는다. 당연히 한자 넣을 공간이 없다. (아니 머리를 잘 썼다면 충분히 있지.) 조합형, 완성형 이 둘은 ASCII 코드와 호환 되도록 만들었기 때문에 코드의 낭비가 있다. 제어 문자를 피해야 하기 때문이다. 또한 1바이트 아스키 코드인지 2바이트 한글 코드인지를 구분해야 하기 때문에 거의 50% 공간을 낭비한다.
제어 문자는 화면 표시용이 아니라 모니터, 프린터, 타자기 등의 커서(문자가 찍힐 위치) 동작을 지시하는 문자이다. 예를 들어 “삐” 소리 내기, 다음 페이지로 넘기기, 한 줄 넘기기, 한 글자 우측 이동, 한 글자 좌측 이동, 행의 좌측 끝으로 이동 등이다. 아직 옛날 O/S와 기계들이 사용되기 때문에 필요하다. (역시 표준이란 쪽수로 결정 된다.)
유니코드(16비트)는 세계 모든 문자를 16비트로 표현하기 때문에 ASCII 호환을 신경 쓸 필요 없었고 그래서 효율적이다. 영국, 미국 입장에선 2배 낭비라 기억/전송 용량 손해고 한중일 모두에게는 이익이다. 유럽인들에겐 이익도 손해도 없다. 프로그래머 입장에서도 다루기 편해서 좋다.
ASCII와의 호환성을 위해 만든 유니코드(8비트 확장 가능)는 제어 문자를 피해야 하는 문제가 있어 복잡하다. 2바이트 유니코드를 3바이트로 변환하는 방법이 있다. 영국, 미국은 1바이트로 기존과 동일, 유럽은 2바이트로 16비트와 같은 용량, 한국은 3바이트로 불리해진다. 일본은 100개만 있으면 되니까 2바이트로 충분할 것이다.
ASCII와의 호환성을 위해 만든 유니코드(8비트 확장 가능)는 제어 문자를 피해야 하는 문제가 있어 복잡하다. 2바이트 유니코드를 3바이트로 변환하는 방법이 있다. 영국, 미국은 1바이트로 기존과 동일, 유럽은 2바이트로 16비트와 같은 용량, 한국은 3바이트로 불리해진다. 일본은 100개만 있으면 되니까 2바이트로 충분할 것이다.
| 위치 | 초성 | 위치 | 중성 | 위치 | 종성 | 분해 |
| 0 | ㄱ | 0 | ㅏ | 0 | ||
| 1 | ㄲ | 1 | ㅐ | 1 | ㄱ | ㄱ |
| 2 | ㄴ | 2 | ㅑ | 2 | ㄲ | ㄱㄱ |
| 3 | ㄷ | 3 | ㅒ | 3 | ㄳ | ㄱㅅ |
| 4 | ㄸ | 4 | ㅓ | 4 | ㄴ | ㄴ |
| 5 | ㄹ | 5 | ㅔ | 5 | ㄵ | ㄴㅈ |
| 6 | ㅁ | 6 | ㅕ | 6 | ㄶ | ㄴㅎ |
| 7 | ㅂ | 7 | ㅖ | 7 | ㄷ | ㄷ |
| 8 | ㅃ | 8 | ㅗ | 8 | ㄹ | ㄹ |
| 9 | ㅅ | 9 | ㅘ | 9 | ㄺ | ㄹㄱ |
| 10 | ㅆ | 10 | ㅙ | 10 | ㄻ | ㄹㅁ |
| 11 | ㅇ | 11 | ㅚ | 11 | ㄼ | ㄹㅂ |
| 12 | ㅈ | 12 | ㅛ | 12 | ㄽ | ㄹㅅ |
| 13 | ㅉ | 13 | ㅜ | 13 | ㄾ | ㄹㅌ |
| 14 | ㅊ | 14 | ㅝ | 14 | ㄿ | ㄹㅍ |
| 15 | ㅋ | 15 | ㅞ | 15 | ㅀ | ㄹㅎ |
| 16 | ㅌ | 16 | ㅟ | 16 | ㅁ | ㅁ |
| 17 | ㅍ | 17 | ㅠ | 17 | ㅂ | ㅂ |
| 18 | ㅎ | 18 | ㅡ | 18 | ㅄ | ㅂㅅ |
| 19 | ㅢ | 19 | ㅅ | ㅅ | ||
| 20 | ㅣ | 20 | ㅆ | ㅅㅅ | ||
| 21 | ㅇ | ㅇ | ||||
| 22 | ㅈ | ㅈ | ||||
| 23 | ㅊ | ㅊ | ||||
| 24 | ㅋ | ㅋ | ||||
| 25 | ㅌ | ㅌ | ||||
| 26 | ㅍ | ㅍ | ||||
| 27 | ㅎ | ㅎ |
위의 표는 초성, 중성, 종성 위치 값이다. 유니 코드 조립 방법은 아래와 같다. 왜 이 간단한 방법을 한국인들은 생각하지 못 했을까? 조합형도 이보다 못 하고, 완성형은 완전히 실망이다. 아직 우리가 어설픈 시절에 만든 것이라 어쩔 수 없다.
유니코드 = 한국코드 시작 위치 + 3차원배열(초성, 중성, 종성)
유니코드 = 한국코드 시작 위치 + 초성*588 + 중성*28 + 종성
유니코드 = 한국코드 시작 위치 + 초성*588 + 중성*28 + 종성
588 = 21*28
2. 문자 이미지(활자) 조립
으이의응잉읭, 쁘빠뽜쁣빫뽧
- 초성 6벌 : 모음의 위치(수평선/수직선/수평수직결합)로 구분
- 중성 2벌 : 받침 유무로 구분(세로 길이 차이)
- 종성 1벌
문자 코드를 보고 이미지를 찾아 조립해서 화면에 표시해야 한다. 알파벳은 아주 쉽겠지만 한글은 초성, 중성, 종성을 모아서 정사각형에 배치해야 한다. 이런 문제로 인해서 한글도 한자처럼 인쇄, 활자, 타자기 분야에서 서양에 비해 불리했다. 최소한 모양이 예쁘게 나오려면 6+2+1=9벌의 자모음 형상(활자)이 필요하다. 이런 조합은 컴퓨터 시대이기에 가능했고, 인쇄, 활자, 타자기 시절에는 불가능했다. 1만 개의 한자/한글 활자를 1만 개의 서랍에서 찾아 조립하는 것보다는 1쪽을 목판으로 파는 것이 낫다.
예쁜 모양을 포기하고 최소의 이미지(활자)로 조립하려면 자음 1벌과 모음 2벌(받침 유무 구분)로 위치만 살짝 바꾸어 조립하는 방법도 있다. 값 싸고 모양도 그리 나쁘지는 않다. 왜냐하면 자음의 크기를 보면 거의 비슷하기 때문이다. 또는 그냥 알파벳처럼 옆으로 풀어쓰는 방법도 있다. (ㅇㅏㄹㅡㅁㄷㅏㅂㄷㅏ.) 또는 초성, 중성만 조립하고 받침만 옆으로 풀어쓰는 방법도 있다. (아르ㅁ다ㅂ다.) 또는 받침만 기준선 밑으로 붙이는 방법이 있는데 옛날 타자기에서 사용하는 방법이다.
아래 코드는 Excel VB Macro에서 유니코드 한글 음소를 분리하는 예제 함수이다.
Public Function split_sound(a)
'한글 초중종 음소 분리
k = Len(a)
split_sound = ""
If k = 0 Then Exit Function
For i = 1 To k
d = Mid(a, i, 1)
b = AscW(d)
If b >= -21504 And b <= -10333 Then '한글이라면
n = (b + 21504)
c1 = Int(n / 588)
c2 = Int((n Mod 588) / 28)
c3 = (n Mod 28)
split_sound = split_sound & Mid("ㄱㄲㄴㄷㄸㄹㅁㅂㅃㅅㅆㅇㅈㅉㅊㅋㅌㅍㅎ", c1 + 1, 1)
split_sound = split_sound & Mid("ㅏㅐㅑㅒㅓㅔㅕㅖㅗㅘㅙㅚㅛㅜㅝㅞㅟㅠㅡㅢㅣ", c2 + 1, 1)
If c3 > 0 Then split_sound = split_sound & Mid("★ㄱㄲㄳㄴㄵㄶㄷㄹㄺㄻㄼㄽㄾㄿㅀㅁㅂㅄㅅㅆㅇㅈㅊㅋㅌㅍㅎ", c3 + 1, 1)
Else
split_sound = split_sound & d
End If
Next i
End Function
3. 키보드 입력 처리
- 2벌식 자판 : 자음, 모음만 구분, 음절 구분 어려움(N 바이트 코드)
- 3벌식 자판 : 초성, 중성, 종성 구분, 음절 구분 쉬움(3 바이트 코드)
키보드 입력에서 음절 구분을 하여 문자 코드를 만들어야 한다. 3벌식 자판인 경우는 음절 구분과 조립이 아주 쉽다. 문제는 사람들이 이 효율적인 자판을 사용하지 않는 것이다. 습관의 힘에 의해서 2벌식을 사용하기 때문에 약간의 프로그램이 필요하다. 영어 자판도 2가지 종류가 있는데 옛날 기계식 타자기 때 개발한 비효율적 QWERTY(좌측 상단 배치 순서임) 방식을 컴퓨터 시대에도 사용하고 있다. 음절 조립은 입력한 문자에 따른 상태 변화도를 그리면 간단하게 프로그램 할 수 있다.
- 자+모+자+모 = (자+모)+(자+모) = 다리
- 자+모+자+자+모 = ((자+모)+자)+(자+모) = 달기
- 자+모+자+자+자+모 = (((자+모)+자)+자)+(자+모) = 닭이
다음에 자+모 조합이 나와야 바로 앞 음절이 끝나는 걸 알 수 있다. 고로 다음 음절까지 기다리는 게 필요한데 영어 자판 처리 프로그램에는 다음 자+모 조합을 기억하는 기능이 없어 한글화 하면 잘 안 되기도 한다. 그래서 마지막 글자는 처리되지 않고 사라지는 경우가 있다. 고로 마지막에 일부러 공백을 몇 개 넣어야 한다. 예로 Unix 사용하는 Mac PC에서 그렇다.
그러니까 화면의 이미지는 세종대왕의 지시에 따라 한자처럼 정사각형에 몰아넣어야 하고, 키보드(타자기) 입력은 알파벳처럼 옆으로 풀어 입력하니 음절을 구분해서 모아야 한다. 이 때 문자 코드가 조합형이나 유니코드(16비트)이면 음소, 음절 구분이 쉽기 때문에 코드 조립도 쉽고, 코드에서 음소를 찾아 화면에 문자 이미지 구성하기도 쉽다.
4. 완성형 코드 ↔ 음소 분리
그런데 우리가 사용하는 윈도우즈 O/S는 불행히도 완성형을 사용한다. 코드 조립도 어렵고, 코드를 보고 음소를 분리해서 이미지를 찾아 조립하는 것도 어렵다. 이 문제 해결을 위해서 완성형 코드를 음소로 분리하여 대응시킨 표를 만들어야 한다. 그 표는 이 글 마지막에 첨부. 이 표를 완성형으로 저장한 후에 초성, 중성, 종성 3차원 행렬을 이용해서 음소에서 완성형 코드를 찾는다.
그와 반대로 완성형 코드에서 음소를 분리해서 문자 이미지를 조립하는 것은 좀 복잡하다. 아래 링크를 보고 완성형 코드와 음소 대응표는 쉽게 만들 수 있다. 문제는 완성형 코드는 연속이 아니란 것이다. 완성형 + CP949에서 한글 영역에 해당하는 사각형을 보면 중간에 건너 뛰는 빈 공간이 상당히 많다. 이것을 연결해 주는 약간의 계산이 필요하다. 그렇게 하면 연속적인 배열에서 아주 빠른 검색이 가능하다.
완성형 한글 + CP949 문자 코드
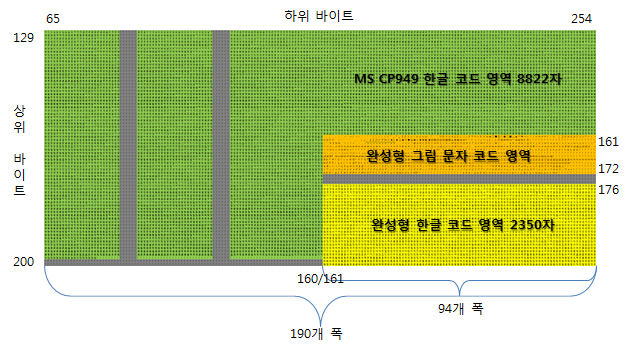

상위 바이트란 먼저 나오는 바이트이다. 상위 바이트가 128 이상이면 하위 바이트도 묶어 해석하란 의미다. 고로 2바이트 공간에서 50% 공간은 사용할 수 없게 된다. 상위 바이트가 127 이하이면 상위 하위 구분 없이 7비트 아스키로 해석한다. 아스키에서 65 미만은 제어 문자라 피해야 한다. 그래서 코드가 연속적이지 않고 불연속적이다. 그럼 메모리 낭비다. 약간의 계산으로 불연속적 코드를 연속적 코드로 변형할 수 있다. 연속적 코드로 변형한 후에 검색을 하면 된다.
그와 반대로 완성형 코드에서 음소를 분리해서 문자 이미지를 조립하는 것은 좀 복잡하다. 아래 링크를 보고 완성형 코드와 음소 대응표는 쉽게 만들 수 있다. 문제는 완성형 코드는 연속이 아니란 것이다. 완성형 + CP949에서 한글 영역에 해당하는 사각형을 보면 중간에 건너 뛰는 빈 공간이 상당히 많다. 이것을 연결해 주는 약간의 계산이 필요하다. 그렇게 하면 연속적인 배열에서 아주 빠른 검색이 가능하다.
완성형 한글 + CP949 문자 코드
상위 바이트란 먼저 나오는 바이트이다. 상위 바이트가 128 이상이면 하위 바이트도 묶어 해석하란 의미다. 고로 2바이트 공간에서 50% 공간은 사용할 수 없게 된다. 상위 바이트가 127 이하이면 상위 하위 구분 없이 7비트 아스키로 해석한다. 아스키에서 65 미만은 제어 문자라 피해야 한다. 그래서 코드가 연속적이지 않고 불연속적이다. 그럼 메모리 낭비다. 약간의 계산으로 불연속적 코드를 연속적 코드로 변형할 수 있다. 연속적 코드로 변형한 후에 검색을 하면 된다.
모든 내부 처리는 유니 코드로 하고 마지막 저장할 때만 유니코드 → 완성형 변환을 해 준다. 이 변환을 할 때 필요한 빠른 검색 표를 만드는 것에 관한 얘기다. 3차원 배열에서 유니코드를 검색하거나 반대로 완성형 코드를 검색하는 것이다. 요즘 컴퓨터는 대부분 내부적으로 유니코드를 사용하고 있을 것이다.
대선은 결선 투표제, 총선은 비례 대표제가 그래도 가장 합리적이지?
예를 들어 다음과 같은 상황이라고 하자.
- 1등 40% 독재당
- 2등 30% 도전당
- 3등 20% 기회당
- 4등 10% 포기당
한국과 같은 선거 제도론 겨우 40%의 지지를 받는 독재당에서만 대통령이 나오고, 국회의원도 과반수이상을 독재당이 가져갈 수 있다. 50% 이상의 지역구에서 독재당이 1등으로 당선되기만 하면 되니까. 다수 대표제 : 40% 받은 1등이 100%를 다 먹는 방식
국민의 지지가 위와 같다면 국회에선 위와 비슷한 비율로 국회의원이 당선되어야 한다. 그게 비례 대표제다. 국민의 지지에 비례해서 의석을 할당 받는 것이다. 오로지 1명을 뽑아야 하는 대통령 선거에선 1등과 2등을 가린 후에 이 둘 중에서 선택해야 그래도 국민의 반감을 사지 않은 자가 대통령이 되고, 대통령이 된 자도 자기 지역 이외의 사람들을 신경 쓰게 된다. 그게 결선 투표제다. 무조건 50% 이상 지지를 받은 자가 대표가 된다.